Latest

The Memory Wall: Past, Present, and Future of DRAM
The debate about Moore’s Law often centers on logic, but the more consequential slowdown has been in DRAM. For decades, DRAM bit density doubled roughly every 18 months—over 100× per...
The Memory Wall: Past, Present, and Future of DRAM
The debate about Moore’s Law often centers on logic, but the more consequential slowdown has been in DRAM. For decades, DRAM bit density doubled roughly every 18 months—over 100× per...
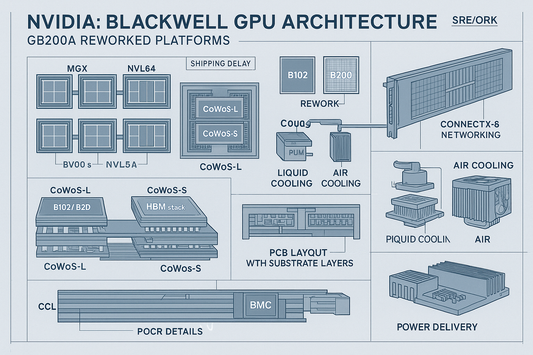
Blackwell Shipment Delays and GB200A Platform R...
Nvidia’s Blackwell program is facing material headwinds to high-volume production. Packaging constraints and system-level challenges have reduced shipment volumes in Q3/Q4 2024 and into H1 2025. Hopper shipments are being...
Blackwell Shipment Delays and GB200A Platform R...
Nvidia’s Blackwell program is facing material headwinds to high-volume production. Packaging constraints and system-level challenges have reduced shipment volumes in Q3/Q4 2024 and into H1 2025. Hopper shipments are being...
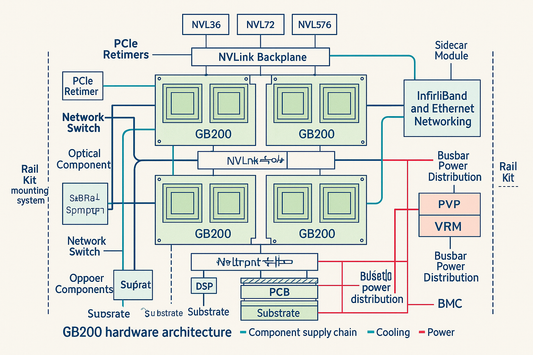
GB200 Hardware Architecture: Supply Chain and B...
Nvidia’s GB200 raises accelerator performance through a tightly coupled Grace–Blackwell architecture and a rack-scale NVLink fabric. The tradeoff is a step-function increase in deployment complexity: power density, liquid-cooling options, NVLink...
GB200 Hardware Architecture: Supply Chain and B...
Nvidia’s GB200 raises accelerator performance through a tightly coupled Grace–Blackwell architecture and a rack-scale NVLink fabric. The tradeoff is a step-function increase in deployment complexity: power density, liquid-cooling options, NVLink...
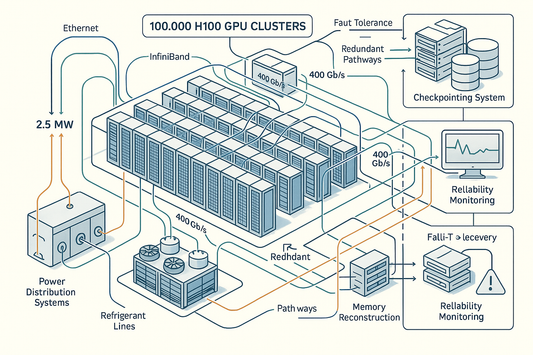
Designing 100,000 H100 Clusters: Power and Faci...
Frontier-scale training has not advanced primarily because training compute per model has plateaued near GPT-4 levels (~2×10^25 FLOP). Several recent models allocated comparable or greater FLOPs but fell short due...
Designing 100,000 H100 Clusters: Power and Faci...
Frontier-scale training has not advanced primarily because training compute per model has plateaued near GPT-4 levels (~2×10^25 FLOP). Several recent models allocated comparable or greater FLOPs but fell short due...

OpenAI Chip Team Ramps Hiring and Talent Acquis...
OpenAI’s long-rumored silicon effort has shifted from talk to execution, marked by an aggressive hiring wave that has expanded a small team to a meaningful headcount. The common thread across...
OpenAI Chip Team Ramps Hiring and Talent Acquis...
OpenAI’s long-rumored silicon effort has shifted from talk to execution, marked by an aggressive hiring wave that has expanded a small team to a meaningful headcount. The common thread across...
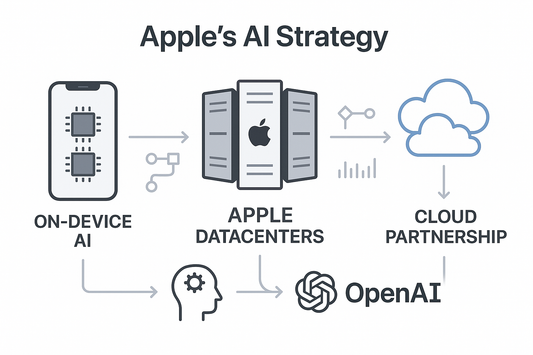
Apple's AI Strategy Across On Device, Apple Dat...
Below is a pragmatic routing + economics playbook you can ship against the reality you described (small Apple GPU buys; M2 Ultra build-out; frontier features via partners). 1) Routing policy:...
Apple's AI Strategy Across On Device, Apple Dat...
Below is a pragmatic routing + economics playbook you can ship against the reality you described (small Apple GPU buys; M2 Ultra build-out; frontier features via partners). 1) Routing policy:...