Latest
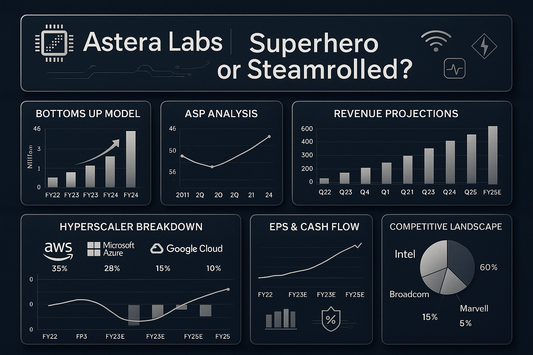
Astera Labs Units, ASP, and Revenue: Bottom Up ...
The current build-out of AI infrastructure is elevating not only GPU vendors but also smaller, high-margin enablers in connectivity. This analysis constructs a bottoms-up model for Astera Labs—by product family...
Astera Labs Units, ASP, and Revenue: Bottom Up ...
The current build-out of AI infrastructure is elevating not only GPU vendors but also smaller, high-margin enablers in connectivity. This analysis constructs a bottoms-up model for Astera Labs—by product family...

CXL’s Role in the AI Era: A Critical Reassessment
Executive Summary CXL was pitched to enable heterogeneous compute, memory pooling, and composable servers. Two years into the AI cycle, most large-scale deployments have prioritized NVLink- and Ethernet/InfiniBand-class fabrics over...
CXL’s Role in the AI Era: A Critical Reassessment
Executive Summary CXL was pitched to enable heterogeneous compute, memory pooling, and composable servers. Two years into the AI cycle, most large-scale deployments have prioritized NVLink- and Ethernet/InfiniBand-class fabrics over...

Race for AI Datacenter Space: GW-scale Buildout...
Overview Demand for large-scale AI clusters has shifted the bottleneck from accelerators to datacenter capacity. Power availability, grid interconnects, and facility systems—not chips—will determine the pace of AI deployment. Training...
Race for AI Datacenter Space: GW-scale Buildout...
Overview Demand for large-scale AI clusters has shifted the bottleneck from accelerators to datacenter capacity. Power availability, grid interconnects, and facility systems—not chips—will determine the pace of AI deployment. Training...
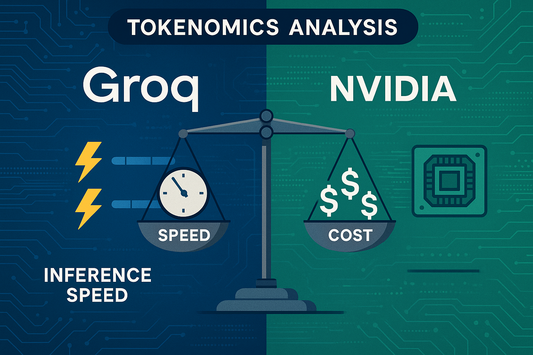
Groq Versus NVIDIA: Tokens per Second, J/token,...
Context and Claim Groq has drawn attention with demos of Mixtral 8×7B Instruct on its inference API, showing up to ~4× higher per-sequence throughput than common GPU services while pricing...
Groq Versus NVIDIA: Tokens per Second, J/token,...
Context and Claim Groq has drawn attention with demos of Mixtral 8×7B Instruct on its inference API, showing up to ~4× higher per-sequence throughput than common GPU services while pricing...
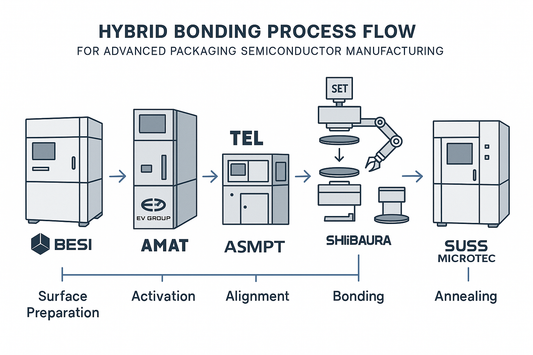
Hybrid Bonding Process Flow, Advanced Packaging...
Why Hybrid Bonding Matters Hybrid bonding is poised to reshape semiconductor design and manufacturing more profoundly than recent lithography transitions. While traditional 2D scaling continues at a slower pace, bumpless...
Hybrid Bonding Process Flow, Advanced Packaging...
Why Hybrid Bonding Matters Hybrid bonding is poised to reshape semiconductor design and manufacturing more profoundly than recent lithography transitions. While traditional 2D scaling continues at a slower pace, bumpless...
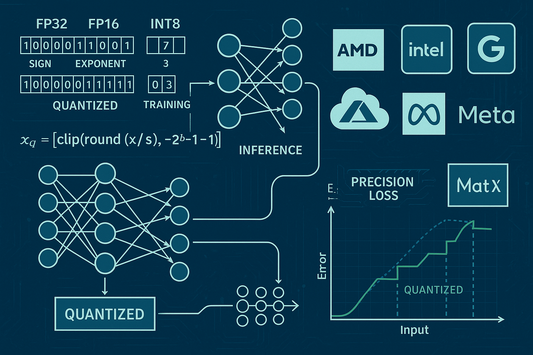
Hardware and Compiler Co-Design for Quantized T...
Why Number Formats Matter Quantization—progressing from 32-bit to 16-bit, 8-bit, and beyond—has delivered a large share of AI hardware efficiency gains. Vendors attribute on the order of 16× of per-chip...
Hardware and Compiler Co-Design for Quantized T...
Why Number Formats Matter Quantization—progressing from 32-bit to 16-bit, 8-bit, and beyond—has delivered a large share of AI hardware efficiency gains. Vendors attribute on the order of 16× of per-chip...